If you’re into systems that can share data among each other in real time, this has been a good week. On Tuesday, Yahoo open sourced its version of the popular Storm stream-processing software that’s able to run inside Hadoop clusters. Then, on Thursday, Facebook detailed a system called Wormhole that informs the platform’s myriad applications when changes have occurred in another, so that each one is working from the newest data possible.
The Yahoo work is actually pretty important. Among the features Hadoop users have been demanding from the platform is a transition from batch-processing-only mode into something that can actually deal with data in real time. The reason for the demand is quite simple: Although being able to analyze or transform data minutes to hours after it’s generated is helpful for certain analytic tasks, it’s not too helpful if you want an application to be able to act on data as it hits the system.
A service like Twitter is a prime example of where Storm can be valuable. Twitter uses Storm to handle tweets so users’ Timelines are up to date and do things like real-time analytics and spotting emerging trends. In fact, it was Twitter that open sourced Storm in 2011 after buying Storm creator Backtype in order to get access to the technology and its developers.
Among web companies, Storm has become quite popular as a stream-processing complement to Hadoop since then. And now Yahoo has made possible a much tighter integration between the two — even to the point that Storm can borrow cycles from batch-processing nodes if it needs some extra juice. That’s a valuable feature — just last week I heard Twitter engineer Krishna Gade bemoan Storm’s auto-scaling limitations during a talk at Facebook’s Analytics @ Web Scale event.

Krishna Gade talking Storm at the Facebook event.
The Storm-on-Hadoop work is among the first of many promised improvements to come thanks to YARN, a major update to the Apache Hadoop 2.0 code that lets Hadoop clusters run multiple processing frameworks simultaneously. Twitter has been using the open source Mesos resource manager to achieve the same general capabilities, but Gade’s colleague Dmitriy Ryaboy said during the same talk that the company is switching to YARN because it expects — probably correctly — much more community effort will go toward continuously improving its capabilities.
Facebook’s Wormhole project isn’t open source (as far as I can tell), but its lessons are still valuable (and LinkedIn has open sourced a similar technology named Kafka). It’s what’s called a publish-subscribe system, which is essentially a concise way of saying that it manages communications between applications that publish information (e.g., updates to a database) and subscribe to the information their fellow applications are publishing. At Facebook, for example, Wormhole sends changes to Facebook’s master user database to Graph Search so that search results are as up to date as possible, or to its Hadoop environment so analytics jobs have the newest data.
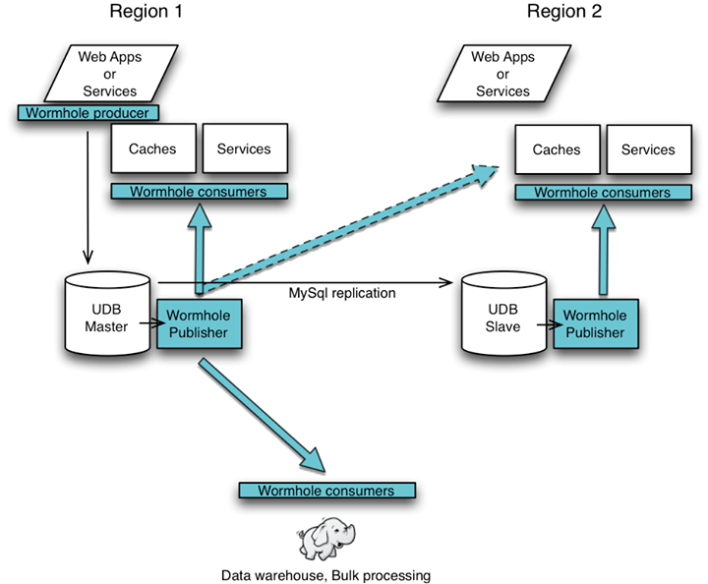
Of course, like all things Facebook (its new Presto interactive query engine comes to mind), Wormhole is built to scale. Latency is in the low milliseconds and, blog post author Laurent Demailly notes
“Wormhole processes over 1 trillion messages every day (significantly more than 10 million messages every second). Like any system at Facebook’s scale, Wormhole is engineered to deal with failure of individual components, integrate with monitoring systems, perform automatic remediation, enable capacity planning, automate provisioning and adapt to sudden changes in usage pattern.”
Although they were developed within separate companies, there’s actually a tie that binds Yahoo’s Storm-in-Hadoop work and Facebook’s Wormhole. As web companies grow from their initial applications into sprawling business composed of numerous applications and services, so too do their infrastructures. To address the differing needs of their various systems at the data level, the companies have begun breaking them down by their latency requirements (i.e., real-time, near real-time and batch, however they choose to word them) and then building tools such as Storm and Wormhole to manage to flow of data between the systems.
We’ve previously explained in some detail how LinkedIn and Netflix have built their data architectures around these principles, and we’ll hear a lot more about how they and other web companies are tackling this situation at Structure next week. Among the speakers are senior engineers and technology executives from Facebook, Google, LinkedIn, Box, Netflix and Amazon.
Feature image courtesy of Shutterstock user agsandrew.